
Binarsity: a Penalization for One-Hot Encoded Features in Linear Supervised Learning
Published in Journal of Machine Learning Research, 2019
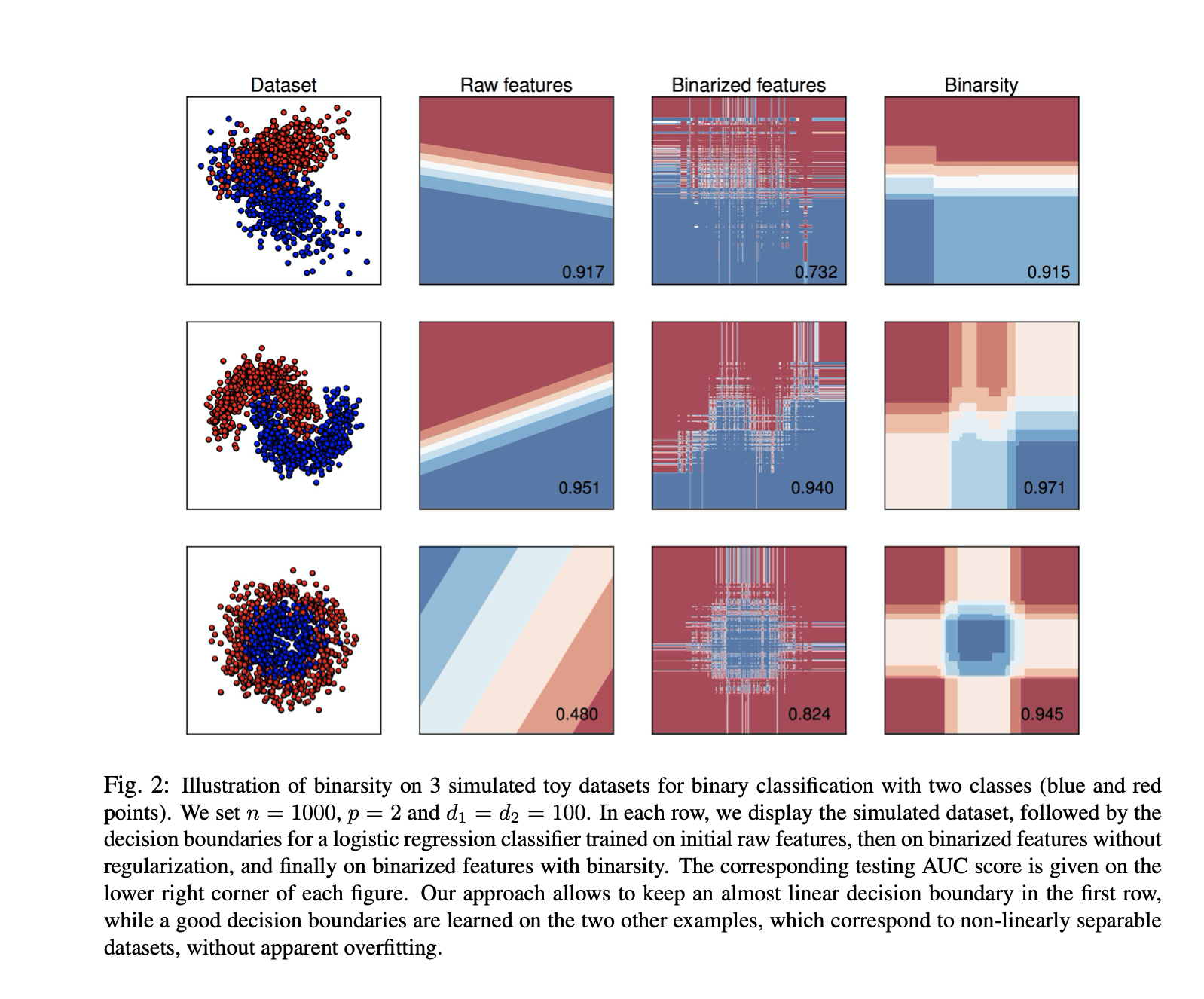
M. Z. Alaya, S. Bussy, S. Gaïffas, A. Guilloux
This paper deals with the problem of large-scale linear supervised learning in settings where a large number of continuous features are available. We propose to combine the well-known trick of one-hot encoding of continuous features with a new penalization called binarsity. In each group of binary features coming from the one-hot encoding of a single raw continuous feature, this penalization uses totalvariation regularization together with an extra linear constraint. This induces two interesting properties on the model weights of the one-hot encoded features: they are piecewise constant, and are eventually block sparse. Non-asymptotic oracle inequalities for generalized linear models are proposed. Moreover, under a sparse additive model assumption, we prove that our procedure matches the state-of-the-art in this setting. Numerical experiments illustrate the good performances of our approach on several datasets. It is also noteworthy that our method has a numerical complexity comparable to standard $\ell_1$ penalization.